

Cuando se utiliza machine learning para ajustar los parámetros de un modelo de forma que sea capaz de realizar inferencias sobre un conjunto de datos con un alto desempeño, esto se hace generalmente minimizando los errores medidos entre las estimaciones del modelo y los datos reales, de manera que su precisión aumente al disminuir los errores de predicción.
Entre las múltiples formas de lograr esto, existe una técnica matemática de gran relevancia llamada descenso de gradiente. Esta estrategia de optimización es básica para algoritmos como las redes neuronales artificiales, por lo que en esta exploración aprenderemos sobre su funcionamiento, definición matemática, ejemplos, y una práctica de experimentación con código en Python.

Inventario recomendado


Métricas de evaluación de modelos de regresión


Programación en Python

Matemáticas: una pizca de cálculo

Algún tentempié

Introducción al descenso de gradientes para optimizar funciones

Hasta el momento, hemos cubierto tres etapas básicas para la generación de modelos de aprendizaje de máquinas:
- Recolección y preparación de datos.
- Entrenamiento del modelo.
- Evaluación del modelo.
Esto nos deja listos para comenzar a explorar de forma más detallada los elementos que pertenecen a cada estadio. Anteriormente, nos hemos embarcado en un riguroso entrenamiento sobre los datos y sus orígenes, por lo que comenzaremos a enfocarnos en las minucias asociadas al entrenamiento del modelo.
Cómo recordarás del recorrido sobre funciones de costo, durante la etapa de entrenamiento, un algoritmo de aprendizaje supervisado minimiza una función de pérdida objetivo, la cual cuantifica las diferencias entre las predicciones del modelo y los valores del conjunto de datos de prueba. La manera en la que se minimiza la función de pérdida es lo que se conoce como optimización. Definamos brevemente este concepto.
Optimizadores en aprendizaje de máquinas
En machine learning, un optimizador es un algoritmo que ajusta los parámetros de un modelo para minimizar una función de pérdida.

Sí es algo similar, y el objetivo perseguido es el mismo, pero el método de mínimos cuadrados es un método de resolución directa para minimizar el error cuadrático medio (MSE), a diferencia de los optimizadores tradicionales, que minimizan la función le pérdida de manera algorítmica (como veremos más adelante).
Entre los diferentes optimizadores, existe uno que funge como base de muchos otros utilizados para entrenar modelos de mayor complejidad, y es el que conoceremos a continuación: el descenso de gradiente.
¿Qué es el descenso de gradiente para machine learning?
El descenso de gradiente es un algoritmo de optimización que se utiliza para encontrar los valores óptimos de los parámetros de un modelo minimizando una función de pérdida mediante un proceso iterativo que calcula el gradiente de la función respecto a los parámetros, y actualiza dichos parámetros en la dirección opuesta al gradiente, con el objetivo de reducir progresivamente el valor de la pérdida (el error).

Es verdad que existen algunos términos que hasta el momento no habíamos mencionado. Llegaremos a comprender esta definición de manera intuitiva, partiendo de un ejemplo.
Descenso de gradiente: ejemplos e intuición
Supongamos que queremos entrenar un modelo de machine learning de aprendizaje supervisado, no importa cuáles son los datos, las variables de entrada o las variables de salida, nos centraremos en el entrenamiento mismo.
Cuando decimos entrenar, como bien se ha dicho, nos referimos a encontrar los valores óptimos de los parámetros del modelo, es decir, hallar los valores de los parámetros de un modelo matemático que logre capturar las relaciones entre los datos, permitiendo realizar inferencias de manera satisfactoria (lo cual, como sabemos, se determina utilizando mediciones de su rendimiento).

El descenso de gradiente funciona mediante pasos, es un proceso iterativo basado en la repetición del cálculo de los valores de la función de costo.
Veamos cómo funciona paso por paso para dejarlo más claro:
1. Supongamos que hemos entrenado un modelo con un solo parámetro (en la regresión lineal, por ejemplo, hemos calculado anteriormente los valores de dos parámetros):
- Después del entrenamiento, vemos que hemos obtenido el valor del parámetro del modelo, ¿cómo sabemos si funciona bien con este parámetro que hemos encontrado utilizando machine learning?
- Para resolver nuestras dudas, hacemos una medición del desempeño del modelo con la función de costo (función de pérdida), y obtenemos un valor alto, es decir, el error es alto, por lo que el modelo no está correctamente optimizado.
- Ahora que tenemos el valor del parámetro y el valor de la función de error, visualizamos estos utilizando un gráfico como el siguiente, donde el eje X corresponde al valor del parámetro, y el eje Y al de la función de costo (el error calculado):

En esta gráfica se puede observar un valor relativamente alto del parámetro, y también un valor alto de la función de costo. Estos valores se ven representados por un punto, es decir, para este valor alto del parámetro obtenemos un error medido también alto, lo que implica que el modelo puede optimizarse más.

Nos ayudará a ilustrar el descenso de gradiente, ya verán más adelante.
Ahora, dibujaremos el punto sobre una curva:

Esta curva representa cómo se suelen comportar los valores de la función de costo respecto a cómo cambia el valor de los parámetros calculados.
Para entender mejor esta curva, recordemos que nuestra misión es minimizar los valores del error calculado (mientras sea más chico, mejor), por lo que debemos buscar la dirección hacia la cual se debe mover Mmerf (el valor del parámetro sobre el eje X), de forma que se desplace hacia un mejor valor del error medido. Esto nos lleva al siguiente paso.

2. Si queremos que el error sea menor, basta con mirar la gráfica: el punto debería dirigirse hacia abajo y hacia la izquierda sobre la curva. Siguiendo la tendencia, al hacer más pequeño el valor del parámetro esto debería provocar que el valor de la función de costo disminuya, acercándose al punto mínimo (el centro de la curva).
Ya escuchaste Mmerf, mueve ese trasero etéreo.

Le hemos dado una dirección correcta, se ha ajustado el valor del parámetro a un valor más chico, y esto ha generado un menor valor de la pérdida calculada (se ha acercado a 0 en el eje Y).
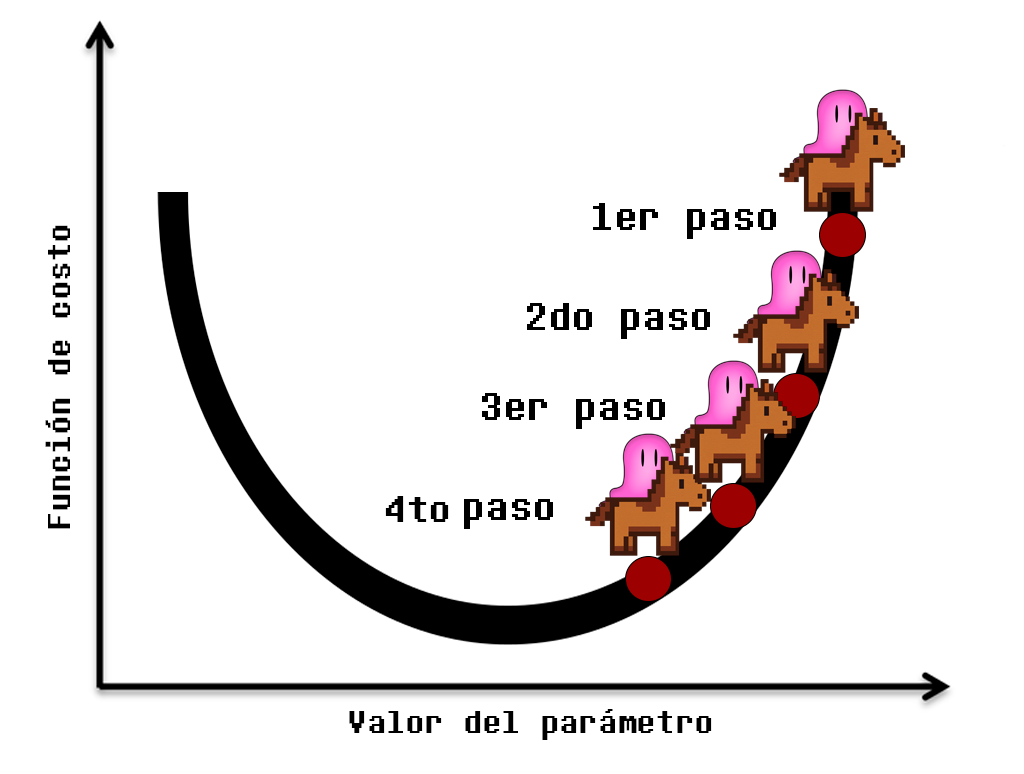
3. Como buscamos el menor valor posible, realizamos otro paso, y volvemos a dirigir a Mmerf hacia un valor más pequeño del parámetro, lo cual lo termina desplazando hacia abajo y la izquierda, quedando en el punto más bajo de la curva:

Con este movimiento, donde se ha determinado hacia dónde debe moverse el valor del parámetro, hemos conseguido alcanzar un mínimo de la función de costo, lo cual se suele denominar «convergencia» (converge a un mínimo de la función).
Esta es la esencia del descenso de gradiente. Se le llama así, porque la idea es descender hacia el mínimo de la función de costo (se minimiza el error) modificando los valores de los parámetros de un modelo, y con gradiente se refiere a la dirección (si se sumará o restará en cantidad a los valores de los parámetros) y magnitud (cuánto se le sumará o restará) a considerar para llegar a la convergencia.
El algoritmo, entonces, consiste en los siguientes pasos:
- Se parte de un punto inicial, generalmente aleatorio.
- Se calcula el gradiente, el cual indica en qué dirección la función de pérdida aumenta o disminuye, lo cual se utiliza para moverse en dirección hacia un mínimo.
- Se ajustan un poco los valores de los parámetros del modelo, esperando reducir el error calculado.
- Se repite el proceso, buscando alcanzar un mínimo después de n iteraciones.

A grandes rasgos, sí. Este proceso se entenderá mucho más en la siguiente sección, donde revisaremos su funcionamiento matemático.
Pero antes debemos de conocer dos elementos básicos del descenso de gradiente que son de gran relevancia en ciencia de datos:
- Tasa de aprendizaje.
- Número de iteraciones.
¿Qué es la tasa de aprendizaje en descenso de gradiente?
La tasa de aprendizaje (learning rate) es un hiperparámetro (por fin llegamos a hablar de nuestro primer hiperparámetro) que controla qué tan grande (magnitud) es cada paso que se da cuando se actualizan los parámetros del modelo durante el descenso de gradiente.
¿Cómo es que funciona?, es simple, se trata de un factor que determina el tamaño de cada movimiento de los parámetros tras cada iteración. Ilustrémoslo.
Recordemos lo que hicimos anteriormente, dimos tres pasos para llegar al mínimo de la función, lo cual podemos mostrar como sigue:

Supongamos que ahora hemos determinado que estos pasos serán más pequeños (tasa de aprendizaje menor), por lo que obtendremos el siguiente movimiento hacia un mínimo de la función de pérdida:

Se puede notar cómo los pasos son más cortos, y esto evita que se llegue al mínimo (el punto más bajo de la curva en el centro). Veamos cómo luce añadiendo un paso adicional:

Aún con el cuarto paso, no alcanzamos el mínimo; por lo tanto, lo ideal es que el tamaño de los pasos (tasa de aprendizaje) sea mayor.
Veamos que sucedería si eleváramos el tamaño de la tasa de aprendizaje:

Aquí podemos notar cómo llegamos al mínimo de la función de pérdida aumentando la tasa de aprendizaje.

En ese caso, se puede llegar a sobrepasar el mínimo, obteniendo de nuevo valores altos de la función de costo, lo cual no resulta favorable:

Se observa que, al incrementar el valor de la tasa de aprendizaje, se llega al otro extremo de la curva, esto implica que se tiene un valor cada vez más pequeño del parámetro estimado (más cerca del 0 en el eje X), lo cual genera que el error vuelva a aumentar (de nuevo el punto está más arriba, en el eje Y). Esto significa que valores más pequeños del parámetro de la función no implica siempre que generen mejores valores en las predicciones, por eso es importante configurar una tasa de aprendizaje que permita una convergencia cercana al mínimo de la función de pérdida.
¿Qué es el número de iteraciones en descenso de gradiente?
Las iteraciones son los pasos repetidos que se realizan en la ejecución del descenso de gradiente para ajustar los parámetros de un modelo con el objetivo de minimizar la función de costo.
Tomemos el caso en el que elegimos una tasa de aprendizaje pequeña y obtuvimos lo observado en la Figura 3.9.7, donde vimos que no llegamos a alcanzar el mínimo del error calculado. Para esto, también podríamos haber añadido más pasos, como se muestra en la Figura 3.9.10:
{kind=link}

Para un valor relativamente bajo de la tasa de aprendizaje, al aumentar el número de iteraciones (pasos), hemos logrado minimizar el error.
Veamos ahora cómo luce el caso inverso, en el que tenemos un número más grande de tasa de aprendizaje, y reducimos los pasos para evitar oscilaciones que no permitan alcanzar el mínimo:

En este caso, utilizando un menor número de iteraciones se alcanza un mejor resultado.
Con esto hemos podido comprender cómo este par de esenciales hiperparámetros se combinan para optimizar la función de error y ajustar los parámetros de un modelo.
En general, se pueden considerar los siguientes problemas al intentar encontrar una convergencia en la función de pérdida:
| Fenómeno al intentar converger | Descripción |
|---|---|
| Sobretiro (Overshooting) | El algoritmo «se pasa» del mínimo en cada paso debido a una tasa de aprendizaje demasiado grande. |
| Oscilación | Los valores de los parámetros rebotan de un lado al otro del mínimo sin estabilizarse. |
| Divergencia | El algoritmo no solo no converge, sino que el costo puede incluso aumentar indefinidamente. |
Hasta este punto de la exploración podemos decir que entendemos el fin y proceso generalizado del descenso de gradiente. Para comprender con detalle cómo funciona el algoritmo, revisaremos las definiciones matemáticas.
Descenso de gradiente: definición matemática

En esta sección formalizaremos la definición de descenso de gradiente, y haremos un ejercicio de «cálculo a mano» para observar sus efectos en los parámetros del modelo y su función de pérdida asociada.
Definición (3.16) Descenso de gradiente. El descenso de gradiente es un algoritmo de optimización de primer orden que se utiliza para encontrar un mínimo local de una función de pérdida diferenciable L (nota sobre esto más abajo), la cual evalúa el desempeño de un modelo h(x) sobre un conjunto de datos etiquetados.
{kind=link}
Sea \mathcal{D} = {(x_1, y_1), \dots, (x_N, y_N)} un conjunto de N observaciones, donde cada x_n es una entrada y y_n su etiqueta asociada, un modelo h(x) que pretende modelar las relaciones entre estos valores y sus etiquetas, y produce predicciones \hat{y}_n = h(x_n); y se define una función de pérdida que cuantifica el error entre y_n y \hat{y}_n, de forma individual como:
l(y_n, \hat{y}_n). \tag{3.76}La función de pérdida total sobre el conjunto se expresa como:
L(\mathcal{Y}, \mathcal{\hat{Y}}) = \frac{1}{N} \sum_{i=1}^N l(y_n, \hat{y}_n). \tag{3.77}El descenso de gradiente busca minimizar esta función L ajustando los D parámetros del modelo de forma iterativa en T pasos. Denotamos por \boldsymbol{\theta}^{(t)} \in \mathbb{R}^D el vector de parámetros (número de parámetros del modelo ordenados en un vector) en la iteración t. El algoritmo actualiza simultáneamente todos los parámetros en dirección opuesta al gradiente de la función de pérdida, según la regla
\boldsymbol{\theta}^{(t+1)} = \boldsymbol{\theta}^{(t)} - \gamma^{(t)} \nabla L(\boldsymbol{\theta}^{(t)}), \tag{3.78}donde \boldsymbol{\theta}^{(t)} es el vector de parámetros en la iteración t, \gamma^{(T)} > 0 es la tasa de aprendizaje en la iteración t, y \nabla L(\boldsymbol{\theta}^{(t)}) es el gradiente de la función de pérdida respecto a todos los parámetros, es decir, es el conjunto de las derivadas parciales de la función de pérdida respecto a los parámetros del modelo, y se expresa como sigue:
\nabla L(\boldsymbol{\theta}) = \left( \frac{\partial L}{\partial \theta_1}, \frac{\partial L}{\partial \theta_2}, \dots, \frac{\partial L}{\partial \theta_D} \right), \tag{3.79}Por lo tanto, la actualización de un solo parámetro \theta_d en el paso t puede expresarse como
\theta_d^{(t+1)} = \theta_d^{(t)} - \gamma^{(t)} \frac{\partial L}{\partial \theta_d}(\boldsymbol{\theta}^{(t)}),\tag{3.80}
O utilizando \nabla para denotar la derivada parcial:
\theta_d^{(t+1)} = \theta_d^{(t)} - \gamma^{(t)}\nabla L(\boldsymbol{\theta}_d^{(t)}).\tag{3.81}El procedimiento del descenso de gradiente se repite por un número predefinido de iteraciones T, o hasta que se cumpla una condición de parada, como:
\left| \nabla L(\theta_i) \right| \approx 0,\tag{3.82}lo cual indica que el gradiente es cercano a cero, señalando proximidad a un mínimo.


Nota sobre la terminología de la definición 3.16 🧾
1. ¿Qué significa que el descenso de gradiente es de primer orden?
Cuando decimos que un algoritmo de optimización es de primer orden, nos referimos a que utiliza únicamente la primera derivada (o el gradiente) de la función que se desea minimizar. No usa derivadas de orden superior, como la segunda derivada (Hessiana), que se emplea en algoritmos de segundo orden, como sucede en el método de Newton.
2. ¿Qué significa que la función es diferenciable?
Decir que una función es diferenciable significa que tiene derivada en todos los puntos de su dominio. Esto implica que:
- Su gráfica no tiene saltos ni esquinas (es suave).
- Se puede calcular el gradiente (vector de derivadas parciales) en cada paso, que es lo que necesitamos para hacer actualizaciones en los pasos del descenso.
En el contexto del descenso de gradiente, esto se traduce en que la función de pérdida L(\theta) debe ser diferenciable con respecto a los parámetros del modelo \theta_d para que podamos aplicar la regla de la Ecuación 3.78.
Si no lo fuera, no podríamos calcular el gradiente y el algoritmo dejaría de ser aplicable.
Ejemplo de cálculo de un parámetro con descenso de gradiente
Todo cobrará más sentido cuando presenciemos cómo es que el descenso de gradiente realiza su magia. Para esto, ajustaremos una función de la forma h(x) = \theta x, donde \theta es el único parámetro del modelo.
Si lo notan, se puede decir que es la ecuación de una recta (la que obtenemos mediante regresión lineal) sin su segundo parámetro, es decir, sin intercepción.
Para esto, utilizaremos el conjunto de datos:
\mathcal{D} = \lbrace{(x_1 = 1, y_1 = 2), (x_2 = 2, y_2 = 4)}\rbraceEs decir, un conjunto de datos con dos observaciones, como se muestra en la siguiente tabla:
| Entrada x_n | Salida y_n |
|---|---|
| 1 | 2 |
| 2 | 4 |
Aquí los valores corresponden a cualquier escenario que puedas idear, por ejemplo, se podría decir que x_n es el número de hamburguesas que puedes comprar en un restaurante, y y_n su correspondiente precio:
- x_1=1, y_1=2 (1 hamburguesa por 2 dólares).
- x_2=2, y_2=4 (2 hamburguesas por 4 dólares).
En realidad, puedes imaginar cualquier caso, lo que importa es la forma en que modelaremos la relación entre estas variables.
Ahora queremos ajustar el parámetro de nuestro modelo para predecir nuevos valores de y respecto a nuevos valores de x, ¿qué función de pérdida nos serviría para evaluar un modelo de regresión?
Utilizaremos la función de pérdida del error cuadrático medio, que definimos en otra travesía de esta manera:
L(\theta) = \frac{1}{N} \sum_{n=1}^N (y_n - \hat{y}_n)^2,\tag{3.83}Dado que conocemos la forma de la función y el valor de N (tenemos dos ejemplos de entrenamiento), sustituimos en (3.83) y obtenemos
L(\theta) = \frac{1}{2} \sum_{n=1}^{N} (y_n - \theta x_n)^2\tag{3.84}donde \theta x_n=\hat{y}_n, es decir, es el valor calculado por el modelo parametrizado por los parámetros \theta.
Gradiente de la función de pérdida
Ahora calculamos el gradiente, que, como vimos en (3.79) y (3.80) se trata de la derivada de L(\theta) respecto a \theta:
\begin{align}
\nabla L(\theta) &= \frac{d}{d\theta} L(\theta)\tag{3.85} \\
&= -\frac{1}{N} \sum_{n=1}^{N} x_n (y_n - \theta x_n), \tag{3.86}
\end{align}donde L(\theta) es la función definida en 3.84(\theta). Veamos cómo aplicamos esta derivada para optimizar el modelo.
Hiperparámetros y aplicación de descenso de gradiente
Los hiperparámetros a ajustar para hacer descenso de gradiente son los siguientes:
- Tasa de aprendizaje: \gamma = 0.1
- Número de iteraciones: T= 3
Además, inicializaremos el valor del parámetro en cero:
- \theta_0 = 0
Con esto listo, comencemos a hacer el descenso de gradiente:
Iteración 1
Sustituimos en la Ecuación (3.86) con:
- \theta_0 = 0 (valor del parámetro).
- x_n = 2 (valor de entrada).
- y_n = 1 (valor de salida).
- N = 2 (número de ejemplos de entrenamiento).
Quedando:
\nabla L(\theta^{(0)}) = -\frac{1}{2} [1(2 - 0) + 2(4 - 0)] = -\frac{1}{2}(2 + 8) = -5.\tag{3.87}Esto quiere decir que el gradiente es igual a -5. Utilizamos este valor y sustituimos en (3.78) con:
- \theta_0^{(0)} = 0 (valor inicial, en el paso 0).
- \gamma = 0.1 (tasa de aprendizaje).
- \nabla L(\theta^{(0)})= -5 (valor de salida).
Quedando:
\theta^{(1)} = \theta^{(0)} - \gamma \cdot \nabla L(\theta^{(0)}) = 0 - 0.1 \cdot (-5) = 0.5.\tag{3.88}¿Qué significa esto? Que hemos aplicado el gradiente calculado, el cual nos dice en qué dirección se puede minimizar la función de pérdida, y al aplicarlo obtuvimos un nuevo valor para el parámetro \theta_0 , que pasó de ser 0 a 0.5.
¿Cómo comprobamos que esto mejora el desempeño del modelo? Calculemos la función de pérdida antes y después de aplicar el cambio al parámetro.
Función de pérdida (rendimiento del modelo) antes de aplicar el descenso de gradiente (utilizando la Ecuación (3.84)):
L(\theta^{(0)}) = \frac{1}{4} \left[(2 - 0)^2 + (4 - 0)^2\right] = \frac{1}{4}(4 + 16) = 5.\tag{3.89}Ahora, obtenemos el nuevo valor del rendimiento del modelo con el parámetro modificado:
L(\theta^{(1)}) = \frac{1}{4} \left[(2 - 0.5)^2 + (4 - 1)^2\right] = \frac{1}{4}(2.25 + 9) = \frac{11.25}{4} = 2.8125, \tag{3.90}
donde se debe notar que (3.89) y (3.90) son casi el mismo cálculo, salvo que en la segunda ecuación se utilizó el nuevo valor del parámetro \theta. Con este nuevo parámetro, la función de error arrojó un resultado mejor (el error calculado es menor), lo que indica que el modelo mejoró en sus predicciones.
Lo que acabamos de hacer fue sencillo, pero altamente funcional: al encontrar el gradiente (la derivada), multiplicamos este por la tasa de aprendizaje y lo restamos al parámetro, lo cual nos dio un parámetro optimizado que mejoró las capacidades del modelo.
Continuemos con las siguientes dos iteraciones de manera resumida.
Iteración 2
Se calcula el gradiente:
\nabla L(\theta^{(1)}) = -\frac{1}{2} \left[1(2 - 0.5) + 2(4 - 1)\right] = -\frac{1}{2}(1.5 + 6) = -3.75\tag{3.91}Se actualiza el parámetro \theta:
\theta^{(2)} = \theta^{(1)} - \gamma \cdot \nabla L(\theta^{(1)}) = 0.5 + 0.375 = 0.875\tag{3.92}El error antes de aplicar el descenso de gradiente:
L(\theta^{(1)}) = 2.8125\tag{3.93}El error después de aplicar el descenso de gradiente:
L(\theta^{(2)}) = \frac{1}{4} \left[(2 - 0.875)^2 + (4 - 1.75)^2\right] = \frac{1}{4}(1.2656 + 5.0625) = \frac{6.3281}{4} \approx 1.582 \\\tag{3.94}Iteración 3
Se calcula el gradiente:
\nabla L(\theta^{(2)}) = -\frac{1}{2} \left[1(2 - 0.875) + 2(4 - 1.75)\right] = -\frac{1}{2}(1.125 + 4.5) = -2.8125
\tag{3.95}Se actualiza el parámetro \theta:
\theta^{(3)} = \theta^{(2)} - \gamma \cdot \nabla L(\theta^{(2)}) = 0.875 + 0.28125 = 1.15625\tag{3.96}El error antes de aplicar el descenso de gradiente:
L(\theta^{(2)}) \approx 1.582\tag{3.97}El error después de aplicar el descenso de gradiente:
\begin{align}
L(\theta^{(3)}) &= \frac{1}{4} \left[(2 - 1.15625)^2 + (4 - 2.3125)^2\right] \tag{3.98} \\
&= \frac{1}{4}(0.710 + 2.859) = \frac{3.569}{4} \approx 0.892 \tag{3.99}
\end{align}
Se puede notar que en cada iteración, la función de pérdida disminuye, por lo que hemos encontrado mejores versiones del modelo al modificar el parámetro con descenso de gradiente. En la tabla se puede ver la evolución de los resultados:
| Iteración t | Parámetro \theta^{(t)} | Gradiente \nabla L(\theta^{(t)}) | Error antes de actualizar L(\theta^{(t)}) | Error después de actualizar L(\theta^{(t+1)}) |
|---|---|---|---|---|
| 0 | 0.000 | -5.000 | 5.000 | 2.8125 |
| 1 | 0.500 | -3.750 | 2.8125 | 1.582 |
| 2 | 0.875 | -2.8125 | 1.582 | 0.892 |
| 3 | 1.15625 | — | 0.892 | — |
Es así como evidenciamos el mecanismo interno del descenso de gradiente para optimizar modelos. En lo que concierne a una aplicación de esto a modelos multivariables, solo se aplica la misma actualización pero a todos los parámetros a la vez.
Es un algoritmo sencillo, por lo que encierra una belleza sutil tras bastidores. Un hechizo simple pero poderoso.
Es momento de utilizarlo con Python.
Descenso de gradiente: estudio con Python

Ahora veremos ejemplos de cómo optimizar un modelo de inteligencia artificial con descenso de gradiente en Python, haremos uso de un nuevo conjunto de datos, para lo cual generaremos un modelo con un nuevo propósito.

También puedes previsualizarlo aquí:
Aquí finalizamos nuestro encuentro con el descenso de gradiente. Hemos aprendido cómo funciona, cuáles son sus mecanismos internos, y cómo lo podemos utilizar para entrenar modelos de aprendizaje automático.

En nuestra próxima lección continuaremos con algoritmos de optimización, y exploraremos de qué trata la versión más típica del descenso de gradiente: el descenso de gradiente estocástico.
