

Hasta ahora hemos conocido las características clave de los datos y cómo llevar a cabo su análisis y preprocesamiento, hemos utilizado algoritmos de machine learning para entrenar modelos de regresión y clasificación, y hemos aprendido recientemente cómo las funciones de pérdida miden sus capacidades predictivas, principalmente durante la etapa de entrenamiento. Hoy vamos a detenernos a explorar cómo evaluar el rendimiento final de modelos de machine learning de regresión una vez que sus parámetros son ajustados.
Durante esta travesía conocerás las métricas más utilizadas para medir el desempeño de modelos de regresión, su finalidad, definición, análisis, y el cómo utilizarlas con Python.

Inventario recomendado

Matemáticas: algo de álgebra, probabilidad y estadística

Fundamentos del aprendizaje supervisado




Programación en Python

Algún aperitivo

Métricas de evaluación de modelos de regresión: cuáles y cómo utilizarlas

Después de finalizar el ajuste de los parámetros de un modelo mediante un algoritmo de aprendizaje automático, siempre será necesario evaluar qué tan capaz es de realizar cálculos eficientes sobre datos nuevos. Para esto, se utilizan métricas que operan sobre el conjunto de datos de prueba y un grupo predicciones realizadas con la función obtenida. En esta ocasión, aprenderemos sobre medidas que son frecuentemente utilizadas para evaluar modelos de regresión (modelos que realizan predicciones sobre valores en el espectro continuo), y que son parte medular de todo proceso post-entrenamiento.
{kind=link}

Métricas para evaluar modelos de regresión
Existe una rica diversidad de medidas que puedes utilizar para determinar qué tan bien realiza estimaciones un modelo entrenado con machine learning. Para este fin, podemos utilizar funciones de pérdida como las que hemos visto en la exploración correspondiente, donde podemos recordar las siguientes para modelos de regresión:
- Error cuadrático medio (Mean Squared Error, MSE).
- Error absoluto medio (Mean Absolute Error, MAE).
- Error absoluto porcentual medio (Mean Absolute Percentage Error, MAPE)
- Raíz del error cuadrático medio (Root Mean Square Error, RMSE).
- Raíz del error logarítmico cuadrático medio (Root Mean Squared Logarithmic Error, RMSLE).
- Pérdida de Huber (Huber Loss).
- Pérdida Log-cosh. (Log-Cosh Loss).
- Pérdida cuantílica (Quantile Loss).
- L1 suavizado (Smooth L1).
- Pérdida ∈-insensible (∈-Insensitive Loss).
Pero, además, podemos hacer uso de cálculos como los que ofrecen otras métricas que no forman parte del conjunto de las funciones de pérdida:
- Coeficiente de determinación \text{R}^2.
- Coeficientes de correlación.
A pesar de que las opciones son variadas, aquí nos centraremos en algunas de uso frecuente. Siempre debes tener en cuenta que, dependiendo de las características de tus datos, algunas métricas serán más beneficiosas que otras, por lo que tú tienes la última palabra en cuanto a cuál utilizar.
Las mediciones que revisaremos y pondremos a prueba son:
- Error cuadrático medio (Mean Squared Error, MSE).
- Error absoluto medio (Mean Absolute Error, MAE).
- Coeficiente de determinación \text{R}^2 (R-Squared).
- Coeficiente de correlación de Pearson (Pearson Correlation Coefficient).
Definiciones y usos de métricas de evaluación con ejemplos
Las métricas que estamos a punto de explorar son ampliamente utilizadas para la evaluación de modelos de regresión, y aunque no son las únicas, nos ayudarán a comprender cómo operan y cómo utilizar otras para el mismo fin.
Para abordarlo, plantearemos un nuevo caso para el entrenamiento de un modelo: predicción de precios de casas (un ejemplo típico en machine learning, aunque siempre vigente).
Supongamos que se nos ha dado un conjunto de datos con precios de casas que dependen de características de estas como su tamaño, número de habitaciones, y ubicación:
| Tamaño (m²) | Habitaciones | Ubicación | Precio Real (USD) |
|---|---|---|---|
| 100 | 3 | Suburbio | 150,000 |
| 80 | 2 | Ciudad | 200,000 |
| 120 | 4 | Ciudad | 300,000 |
| 60 | 1 | Suburbio | 100,000 |
| 90 | 3 | Suburbio | 180,000 |
Utilizando esto, nuestra meta es modelar la relación entre las variables de entrada y la variable objetivo.



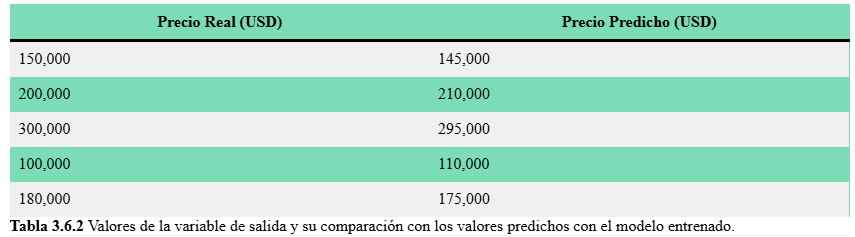
Ya que hemos identificado los aspectos y tareas clave para cumplir nuestro objetivo, supondremos que hemos preprocesado nuestros datos y entrenado un modelo de aprendizaje supervisado que captura las relaciones entre las entradas y salidas, dando el siguiente resultado en las estimaciones realizadas:
| Precio Real (USD) | Precio Predicho (USD) |
|---|---|
| 150,000 | 145,000 |
| 200,000 | 210,000 |
| 300,000 | 295,000 |
| 100,000 | 110,000 |
| 180,000 | 175,000 |
Ya que tenemos predicciones hechas con el modelo, lo que sigue es evaluar su desempeño utilizando las métricas antes propuestas.
Veamos qué son y qué nos dice cada una.
Nota: estamos a punto de comenzar a explorar el funcionamiento e implicaciones de algunas métricas de evaluación. El fin es que conozcas cómo operan y cómo analizar los resultados obtenidos. Es tu obligación como científica/o de datos conocer gran parte de las métricas que tienes a disposición y aprender a utilizarlas de forma oportuna. (Es decir, en lo que concierne a las demás medidas de evaluación, se deja como ejercicio al lector).
{kind=link}
Error cuadrático medio (MSE)
Las primeras dos métricas (MSE y MAE) son funciones de pérdida que operan de la forma que hemos presenciado con anterioridad, comparando los valores del conjunto de datos reales con las predicciones realizadas utilizando el modelo (véase la Imagen 3.4.1). Sin embargo, ambas son ligeramente diferentes, y lo revisaremos a detalle. Comenzaremos con la que ya hemos definido en una excursión pasada.
{kind=link}
El Error Cuadrático Medio (MSE, por sus siglas en inglés de Mean Squared Error) es una métrica que mide la magnitud de los errores en las predicciones de un modelo de regresión, lo cual se hace calculando el promedio de elevar al cuadrado las diferencias entre los valores reales y las predicciones realizadas con el modelo.
Interpretación del MSE
Para interpretar los resultados del Error Cuadrático Medio, se debe considerar lo siguiente:
- Un MSE bajo indica que las predicciones del modelo están más cerca de los valores reales, lo cual es deseable.
- Un MSE alto significa que el modelo tiene un error más grande en las predicciones, lo cual indica un mal ajuste.
También debemos tomar en cuenta que, dado que el MSE es una métrica cuadrática, los errores grandes son penalizados de manera más severa que los errores pequeños (son más vistosos en el resultado, por así decirlo). Esto lo convierte en una métrica sensible a valores atípicos (outliers).

Por eso debemos tener cuidado al preparar los datos para su ingesta.
Cálculo del MSE
Ahora calculamos el MSE, justo como lo dicta la fórmula, con los datos de la Tabla 3.6.2:
{kind=link}
Se obtiene el cuadrado de la diferencia entre las predicciones y los valores reales, y se suman:
\text{Suma de diferencia de errores} = (150,000 - 145,000)^2 + (200,000 - 210,000)^2\\ + (300,000 - 295,000)^2
+ (100,000 - 110,000)^2 + (180,000 - 175,000)^2\text{Suma de diferencia de errores} = (5,000)^2 + (-10,000)^2, (5,000)^2 + (-10,000)^2 + (5,000)^2\text{Suma de diferencia de errores} = 25,000,000 + 100,000,000 + 25,000,000 + 100,000,000\\ + 25,000,000Se suman estos errores y se calcula el promedio, el cual se obtiene dividiendo la suma entre el número total de ejemplos (5 en este caso):
\text{MSE} = \frac{25,000,000 + 100,000,000 + 25,000,000 + 100,000,000 + 25,000,000}{5}\begin{aligned}\text{MSE} &= \frac{275,000,000}{5} \\ &= 55,000,000\end{aligned}Notarás que el MSE obtenido es 55,000,000 USD², lo cual representa el error promedio al cuadrado de las predicciones del modelo en comparación con los valores reales.
Análisis del MSE
En primera instancia, parece un valor alto. Dado que el MSE tiende a crecer con valores grandes en los datos, se puede deber a la presencia de algún valor atípico. Pero, además, se debe considerar la escala, ya que el MSE eleva al cuadrado las diferencias, por lo que el resultado no se encuentra en la escala original de los precios, que rondan entre 150 mil y 300 mil USD, dificultando la interpretación del resultado sin un contexto estadístico adicional. En algunos casos, se usa la Raíz del Error Cuadrático Medio (RMSE), que es simplemente la raíz cuadrada del MSE, para tener una métrica en las mismas unidades que la variable objetivo (en este caso, el precio en USD); o también se puede optar por utilizar alguna otra métrica para complementar la información, como el error absoluto medio, el cual veremos a continuación.

Error Absoluto Medio (MAE)
El Error Absoluto Medio (MAE) es una función de pérdida como el MSE, pero esta mide el error promedio entre las predicciones y los valores reales, sin tomar en cuenta el signo (si las pérdidas son positivas o negativas). Es decir, calcula el promedio de las diferencias absolutas entre las predicciones y los valores reales. La definición matemática concreta de esta y las demás medidas la veremos en la última sección.
Interpretación del MAE
Se considera lo siguiente para interpretar los resultados del MAE:
- Un MAE más bajo indica un error promedio menor, lo que significa que las predicciones están cerca de los valores reales.
- A diferencia del MSE, el MAE no penaliza tanto los errores grandes, ya que no los eleva al cuadrado. Esto lo hace más robusto frente a valores atípicos.

Eso no es la mejor idea, pero es una posibilidad. Recuerda que todo lo que uses para procesar tus datos va de acuerdo a las características que has develado mediante su análisis y manipulación.
Cálculo del MAE
Calculamos el MAE obteniendo la suma del valor absoluto de las diferencias entre los valores estimados y los del conjunto de datos como sigue:
\text{Suma de valor absoluto de errores} = |150,000 - 145,000| + |200,000 - 210,000|+\\ |300,000 - 295,000|+ |100,000 - 110,000|+ |180,000 - 175,000|
\text{Suma de valor absoluto de errores} = 5,000 + 10,000 + 5,000 + 10,000 + 5,000
Y obtenemos el promedio de esta suma:
\begin{aligned}\text{MAE} &= \frac{5,000 + 10,000 + 5,000 + 10,000 + 5,000}{5}\\ &= \frac{35,000}{5}\\ &= 7,000\end{aligned}
Análisis del MAE
El MAE obtenido es 7,000 USD, lo cual significa que, en promedio, las predicciones están a 7,000 USD de los valores reales. Esto es una porción relativamente baja, que ya se trata del 4.6% del valor más bajo en los precios, así como representa el 2.3% del valor más alto. Esto puede indicar que el modelo ha logrado capturar de manera efectiva las relaciones entre las entradas y las salidas.

Como verán en la práctica de Python, con una sola línea de código pueden obtener el valor de una métrica de evaluación, pero aquí estamos desarrollando un poco el proceso para captar la idea de operar con las predicciones y los datos del terreno real para determinar la precisión del modelo. No se asusten, el obtener las métricas es sencillo, lo importante es interpretarlas correctamente.
Coeficiente de Determinación (R2)
Ahora que hemos utilizado un par de funciones de pérdida, vamos con otro tipo de métricas útiles. \text{R}^2 es una medida que, entre otras palabras, indica qué proporción de la variabilidad en los datos es explicada por el modelo.
Cuando decimos que \text{R}^2 explica la variabilidad en los datos, nos referimos a cuánto del cambio o variación en los valores de la variable dependiente (o variable objetivo) puede ser explicado por las variables independientes (entradas o características) del modelo.
En el contexto de nuestro ejemplo, en nuestro conjunto de datos el precio de las viviendas puede variar debido a varios factores, como el tamaño, la ubicación o el número de habitaciones. Esta <<variabilidad>> o <<dispersión>> de los precios en el conjunto de datos es lo que el modelo intenta capturar, y \text{R}^2 cuantifica qué tanto los cambios en las entradas producen cambios en las salidas.
Interpretación del R2
La interpretación de esta métrica es relativamente sencilla:
- \text{R}^2=1 significa que el modelo explica el 100% de la variabilidad en los datos. Esto indica que el modelo se ajusta perfectamente a los datos, ya que todas las predicciones coinciden con los valores reales.
- \text{R}^2=0 indica que el modelo no explica ninguna variabilidad en los datos. En este caso, el modelo no es mejor que simplemente predecir el promedio de los valores reales; en otras palabras, el modelo no está mejorando la predicción en comparación con una simple línea horizontal que representaría el promedio de los valores de salida.
- Un \text{R}^2 negativo es posible si los errores del modelo son tan grandes que el modelo no solo no explica la variabilidad, sino que introduce más error, o sea, más valores alejados del patrón que se asume que describen los datos.
Cálculo del R2
Dado que para su definición matemática se requieren algunos términos más avanzados de estadística, solo mostraremos el resultado de esta medida para nuestro ejemplo, y hablaremos sobre cómo se calcula en la siguiente sección (donde podemos formalizar tranquilamente).
Supongamos que hemos calculado el R^2 y hemos obtenido lo siguiente:
\text{R}^2=0.75Análisis del coeficiente de determinación
Un \text{R}^2 de 0.75 significa que el 75% de la variabilidad en el precio de las viviendas puede ser explicado por los valores de las variables de entrada. El otro 25% de la variabilidad puede deberse a factores no incluidos en el modelo, o a ruido aleatorio. Se puede concluir que, respecto a esta métrica, las variables independientes sí generan cambios en la variable objetivo, y el modelo ha logrado capturar parte de esta variabilidad. El valor es bueno, pero su lejanía de 25 puntos del 100 (0.75 de 1) indica que se puede mejorar la precisión de predicción del modelo evaluado.
Coeficiente de Correlación de Pearson
Por último, pero definitivamente no menos importante, el ya tradicional Coeficiente de Correlación de Pearson, es una medida de la la correlación lineal entre los valores reales y las predicciones del modelo, cuyo valor resultante está en el rango de -1 a 1. Esta métrica indica qué tan dependientes son las salidas de las entradas, y engloba esa dependencia en valores fácilmente interpretables, como vimos que hace \text{R}^2.
{kind=link}
Interpretación del Coeficiente de Pearson
El coeficiente de Pearson se interpreta como sigue:
- Un 1 indica una correlación lineal positiva perfecta: a medida que aumentan o disminuyen los valores reales, aumentan o disminuyen también los valores de las predicciones.
- Un 0 indica que no hay correlación lineal entre las predicciones y los valores reales.
- Un -1 indica una correlación lineal negativa perfecta: a medida que aumentan los valores reales, las predicciones disminuyen, o viceversa, a medida que disminuyen los valores reales, las predicciones aumentan.

Sí, algo así es la idea.
Cálculo del Coeficiente de Correlación de Pearson
Al igual que como hicimos con \text{R}^2, dejaremos para después las operaciones propias de esta métrica. Por el momento, plantearemos que obtuvimos el siguiente valor de correlación:
\rho = 0.85
Análisis del coeficiente de correlación
Al obtener un valor de 0.85, podemos inferir que, al ser cercano a 1, implica que existe una correlación positiva fuerte entre las dos variables en cuestión. Esto significa que, en general, a medida que una variable aumenta, la otra también tiende a aumentar. Además, nótese la relación entre las variables es positiva, pero no perfecta. Es decir, aunque las dos variables se muevan en la misma dirección, puede haber algunos puntos que no sigan esta relación exacta debido a la variabilidad o ruido en los datos. Esto empata con el resultado obtenido en \text{R}^2.
Métricas de evaluación de modelos de regresión con Python

Ha llegado el momento de poner en marcha lo aprendido. En la práctica de hoy obtendremos medidas de evaluación de los modelos de regresión que trabajamos en la introducción a la regresión lineal, y haremos su respectivo análisis.

Puedes previsualizar el contenido aquí:
Para finalizar con este recorrido, haremos mención de la definición matemática de cada métrica para tener consciencia de cómo es que se calculan. No usaremos mucho estas definiciones en el futuro, pero te las dejaré aquí por si llegas a necesitarlas.
Métricas de evaluación de regresión: definiciones matemáticas

Para estas definiciones, consideremos que \mathcal{D} = \lbrace (x_{1},y_{1}),…,(x_{N},y_{N})\rbrace es un conjunto de N datos etiquetados, donde x_n representa las entradas y y_n a la salidas observada correspondiente a cada entrada. Además, se asume que existe un modelo h(x) entrenado con estos datos mediante un algoritmo de aprendizaje supervisado, el cual genera predicciones \hat{y}_n = h(x_n) para cada entrada x_n .
{kind=link}
{kind=link}
Definición (3.12) Error Cuadrático Medio. El Error Cuadrático Medio (MSE) evalúa la precisión promedio de un modelo h(x) como sigue:
\text{MSE} = \frac{1}{N} \sum_{i=1}^N (y_n - \hat{y}_n)^2,\tag{3.65}donde, debe recordarse, \hat{y}_n es la predicción del modelo dadas las variables de la entrada x_n , y y_n es el valor del terreno real del conjunto de datos para esa entrada.
El MSE mide la magnitud del error al cuadrado, penalizando errores grandes más que errores pequeños.
Definición (3.13) Error Absoluto Medio. El Error Absoluto Medio (MAE) calcula el error promedio en valor absoluto entre las predicciones y los valores reales, proporcionando una medida de la distancia media absoluta entre los valores predichos y los valores observados. Se define como:
\text{MAE} = \frac{1}{N} \sum_{i=1}^N |y_n - \hat{y}_n|\tag{3.66}Esta métrica es menos sensible a los valores atípicos que el MSE, ya que no eleva los errores al cuadrado. Nótese que |y_i - \hat{y}_i| representa la diferencia absoluta entre el valor observado y el valor predicho para cada observación.
Definición (3.14) Coeficiente de Determinación. El coeficiente de determinación \text{R}^2 mide la proporción del error cuadrático medio y la varianza. Se calcula mediante la siguiente operación:
\text{R}^2 = 1 - \frac{\sum_{n=1}^N (y_n - \hat{y}_n)^2}{\sum_{n=1}^N (y_n - \bar{y})^2}, \tag{3.67}donde \bar{y} es el promedio de los valores observados y_n . Nótese que el numerador es el MSE, y el denominador la varianza de los datos. Cuando el error cuadrático medio es menor que la varianza total, significa que el modelo ha logrado capturar al menos parte de la variabilidad en los datos. En otras palabras, es indicativo de que el modelo mejora las predicciones en comparación con el uso de una simple línea promedio. Cuanto más se reduzca el error cuadrático medio en comparación con la varianza, mayor será el valor de \text{R}^2, lo cual indica un mejor ajuste del modelo.
Por lo tanto, la métrica \text{R}^2 toma valores entre 0 y 1, donde un valor cercano a 1 indica que el modelo explica bien la variabilidad de los datos, mientras que un valor cercano a 0 indica que el modelo no captura de forma eficiente la variabilidad.
Definición (3.15) Coeficiente de Correlación de Pearson. El Coeficiente de Correlación de Pearson mide la fuerza y dirección de la relación lineal entre las predicciones y los valores observados. Se obtiene como sigue:
\rho = \frac{\sum_{i=1}^n (y_i - \bar{y})(\hat{y}_i - \bar{\hat{y}})}{\sqrt{\sum_{i=1}^n (y_i - \bar{y})^2 \sum_{i=1}^n (\hat{y}_i - \bar{\hat{y}})^2}}, \tag{3.68}donde \bar{y} y \bar{\hat{y}} representan las medias de los valores observados y predichos, respectivamente. El coeficiente r varía entre -1 y 1, donde un valor cercano a 1 indica una fuerte correlación positiva, un valor cercano a -1 indica una fuerte correlación negativa, y un valor cercano a 0 indica poca o ninguna correlación lineal.
Nuestra travesía ha concluido. Hemos aprendido cómo utilizar métricas para evaluar el rendimiento de un modelo de regresión. En nuestra siguiente sesión aprenderemos sobre la evaluación de modelos de clasificación, y con eso estaremos preparando nuestra salida hacia las exploraciones previas a uno de los modelos más icónicos del aprendizaje de máquinas.
