Getting Started with Logistic Regression
With Mlektic, you can perform univariate or multivariate logistic regression (with one or more classes), using the log loss method or by considering various optimization options available in the optimizer_archt module.
Supported optimization methods include: - ‘mle’ - ‘sgd-standard’ - ‘sgd-stochastic’ - ‘sgd-mini-batch’ - ‘sgd-momentum’ - ‘nesterov’ - ‘adagrad’ - ‘adadelta’ - ‘rmsprop’ - ‘adam’ - ‘adamax’ - ‘nadam’
For more details on the optimizer_archt module, please refer to the optimizer_archt documentation.
You can also apply regularization to improve model generalization. The regularizer_archt module supports the following regularization methods: - ‘l1’ (default) - ‘l2’ - ‘elastic_net’
To learn more about the regularizer_archt module, please refer to the regularizer_archt documentation.
For example, you can train a model using logistic regression with standard gradient descent and L1 regularization with the LogisticRegressionArcht module as follows:
import pandas as pd
import numpy as np
from mlektic.logistic_reg import LogisticRegressionArcht
from mlektic import preprocessing
from mlektic import methods
# Generate random data.
np.random.seed(42)
n_samples = 100
feature1 = np.random.rand(n_samples)
feature2 = np.random.rand(n_samples)
target = (3 * feature1 + 5 * feature2 + np.random.randn(n_samples) * 0.5) > 4.0
target = target.astype(np.float32)
# Create pandas dataframe from the data.
df = pd.DataFrame({
'feature1': feature1,
'feature2': feature2,
'target': target
})
# Create train and test sets.
train_set, test_set = preprocessing.pd_dataset(df, ['feature1', 'feature2'], 'target', 0.8)
# Define regularizer and optimizer.
regularizer = methods.regularizer_archt('l1', lambda_value=0.01)
optimizer = methods.optimizer_archt('sgd-standard', learning_rate=0.1)
# Configure the model.
log_reg = LogisticRegressionArcht(iterations=1000, optimizer=optimizer, regularizer=regularizer)
# Train the model.
log_reg.train(train_set)
Epoch 100, Loss: 0.5152596235275269, Accuracy: 0.862500011920929
Epoch 200, Loss: 0.4489741921424866, Accuracy: 0.862500011920929
Epoch 300, Loss: 0.4166463613510132, Accuracy: 0.875
Epoch 400, Loss: 0.39809101819992065, Accuracy: 0.887499988079071
Epoch 500, Loss: 0.38631850481033325, Accuracy: 0.887499988079071
Epoch 600, Loss: 0.37834054231643677, Accuracy: 0.887499988079071
Epoch 700, Loss: 0.37267810106277466, Accuracy: 0.875
Epoch 800, Loss: 0.3685190677642822, Accuracy: 0.875
Epoch 900, Loss: 0.36538296937942505, Accuracy: 0.875
Epoch 1000, Loss: 0.362968385219574, Accuracy: 0.875
To learn more about the LogisticRegressionArcht module, please refer to the LogisticRegressionArcht documentation.
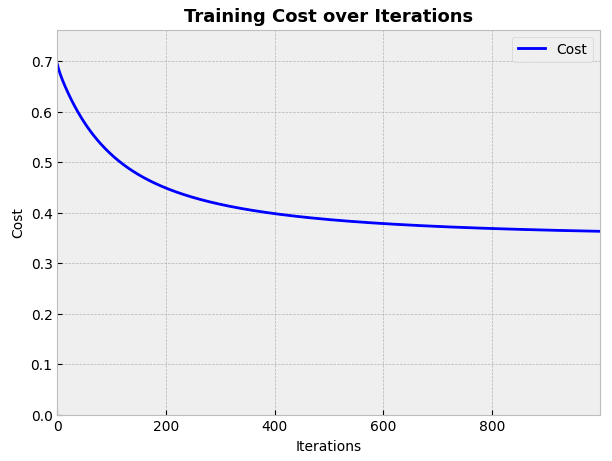
The cost evolution can be plotted with the plot_cost method:
from mlektic.plot_utils import plot_cost
cost_history = log_reg.get_cost_history()
plot_cost(cost_history, dim=(7, 5))
Different evaluation metrics can be obtained:
categorical_crossentropy = log_reg.eval(test_set, 'categorical_crossentropy')
binary_crossentropy = log_reg.eval(test_set, 'binary_crossentropy')
accuracy = log_reg.eval(test_set, 'accuracy')
precision = log_reg.eval(test_set, 'precision')
recall = log_reg.eval(test_set, 'recall')
f1_score = log_reg.eval(test_set, 'f1_score')
confusion_matrix = log_reg.eval(test_set, 'confusion_matrix')
print(f'Categorical Crossentropy: {categorical_crossentropy}')
print(f'Binary Crossentropy: {binary_crossentropy}')
print(f'Accuracy: {accuracy}')
print(f'Precision: {precision}')
print(f'Recall: {recall}')
print(f'F1 Score: {f1_score}')
print(f'Confusion Matrix: \n{confusion_matrix}')
Categorical Crossentropy: 0.22856256365776062
Accuracy: 0.949999988079071
Precision: 1.0
Recall: 0.9090909361839294
F1 Score: 0.952380895614624
Confusion Matrix:
[[10. 0.]
[ 1. 9.]]
Print the parameters obtained by training:
print("Weights:", log_reg.get_parameters())
print("Intercept:", log_reg.get_intercept())
Weights: [[-1.506539 1.506539 ]
[-3.4472232 3.4472237]]
Intercept: [ 2.4116907 -2.4116907]
And make predictions:
prob_prediction = log_reg.predict_prob([2.0, 3.0])
print(f'Predicted probability for class 0: {prob_prediction[0][0]}')
print(f'Predicted probability for class 1: {prob_prediction[0][1]}')
Predicted probability for class 0: 3.1259400623540046e-10
Predicted probability for class 1: 1.0
class_prediction = log_reg.predict_class([2.0, 3.0])
print('Predicted class:', class_prediction[0])
Predicted class: 1
Finally, you can save the model parameters in a JSON format for future use:
log_reg.save_model('logistic_regression_model.json')